
 版权声明:本文为博主原创文章,转载请注明出处:https://twocups.cn/index.php/2024/07/21/58
版权声明:本文为博主原创文章,转载请注明出处:https://twocups.cn/index.php/2024/07/21/58
背景
2024年2月15日,OpenAI发布了其最新的AI视频生成模型——Sora。该模型能够根据用户的文本描述生成高达60秒、1080P的高质量视频。这些视频不仅包含精细复杂的场景,还展现生动的角色表情和复杂的镜头运动。在模型发布时,OpenAI展示了许多宣传视频,但它一直未向公众开放啊!
2024年6月13日,美国初创公司Luma AI宣布推出文生视频/图生视频模型Dream Machine。虽然Dream Machine在文生视频领域无法达到Sora那样精细的运动级别画面表现,并且只支持生成时长5秒的视频,但是它支持图生视频,并且免费对公众开放。
毕竟有了Dream Machine,我就可以让我的表情包全部动起来了。

模型的使用方式很简单
打开Dream Machine官网(https://lumalabs.ai/dream-machine),点击右上角的Try Now进入模型使用结面。如果第一次访问则需要登录,当前只支持Google邮箱,且免费账户每个月有30次的免费生成额度。

模型的使用方案很简单,只需要在输入框内放入图片并且输入文字描述即可。如果你对这个模型的prompt不熟悉,那么就把右下角的Enhance prompt勾选上,这样模型就会自动优化你的提示语句。但如果你对运镜等细节有明确的要求,就可以不勾选。
例如,我就把自己这周团建去重庆拍到的熊猫图片放进去,然后配上文字描述“图中的熊猫开心地啃着竹子”。
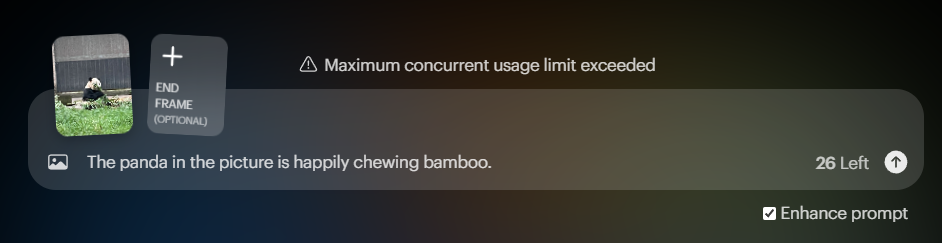
生成出来的结果是这样:

如果你是付费会员,那么大约一分钟内就可以得到生成的视频了。但如果你是免费会员,那么将会长时间在模型生成队列中排队。排队期间可以把页面关掉,不需要一直挂着这个页面等。生成的视频是跟着账户走的,所以创建完视频生成任务后就可以离开了,几个小时后再回来取结果即可。
如果对自己生成的视频不满意,可以点击视频下方的Extend按钮,就可以对生成的视频进行进一步修改。
AI
回想AI在公众视野里破圈快速发展也就近两年的事情,22年12月OpenAI向公众开放GPT-3.5模型的ChatGPT,23年9月开放GPT语音/图像功能,23年10月继续开放多模态能力、GPT4V接口发布。24年5月推出GPT-4O(O是Omni的缩写,意为全能),在多模态方面更加完善了,并且向所有用户开放。
GPT发展迅猛的同时期,其他公司的AI也在各个领域百花齐放。现在的AI已经可以向我们展示他们计算出的结论,表达他们的想法,模拟任意音色,展示任意画面,甚至成为“任何人”。
我微信收藏夹最初收藏的一张图片是我爷爷年轻时候的照片,这次也借着Dream Machine让他动了起来,突然有一种这才是他的感觉。
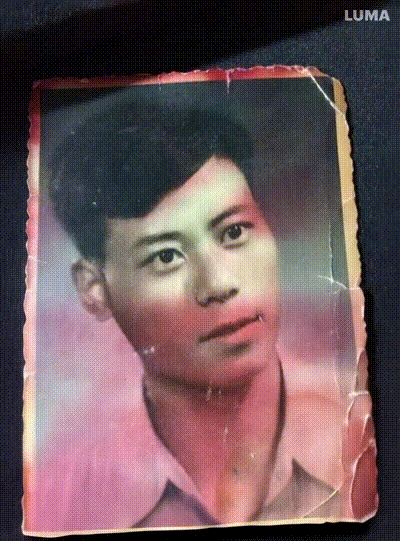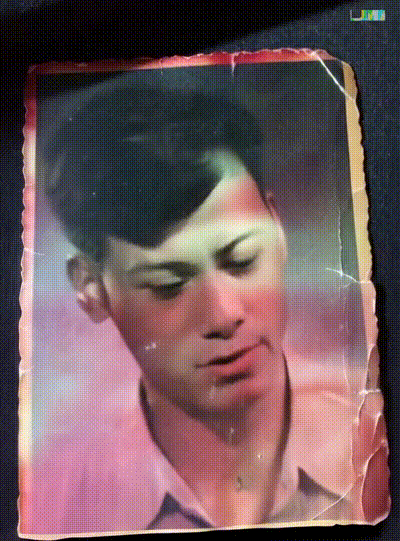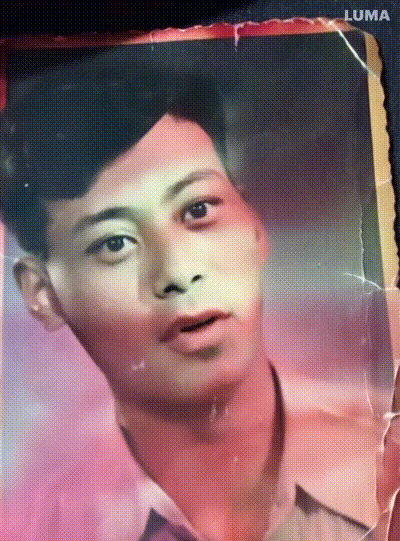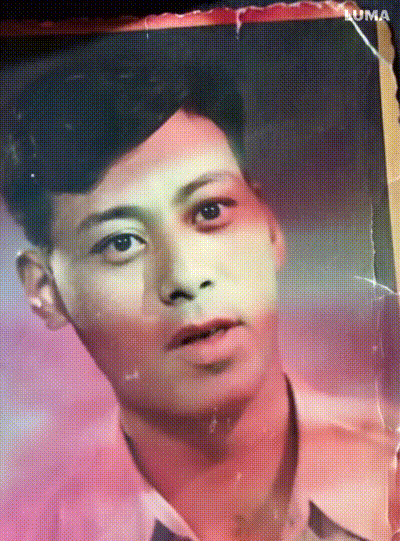
技术可以是温暖的。
这篇文章写得很有意思,Dream Machine虽然功能上比不上Sora,但免费开放给大众使用确实很有吸引力,让普通人也能轻松体验到AI生成视频的乐趣。访问我们的网站 Telkom University Jakarta