
 版权声明:本文为博主原创文章,转载请注明出处:https://twocups.cn/index.php/2023/08/31/55/
版权声明:本文为博主原创文章,转载请注明出处:https://twocups.cn/index.php/2023/08/31/55/
一、背景
今年二月份,Chat GPT 突然迎来爆火,让我深切感知到时代真的在飞速变革。当我还在感慨人工智能时代来临很迅猛的时候,各类 AI 模型及其应用都已经不断推陈出新,诸如备受瞩目的 AIGC 等。我这几天在 ATA 中读到一篇文章,深入探讨了如何将大型语言模型(LLM)与手淘首猜推荐相融合,以优化手淘推荐机制的效果。这让我很感慨,现在各种AI模型的蓬勃发展愈发显著。
我自己在人工智能领域的实际应用是很有限的,主要局限于利用 Chat GPT 协助思路整理。我之前也玩过一段时间 AIGC,然而由于其生成图片涉及版权问题,所以我也只能用来自我消遣一下。最近在研究 Arduino,这玩意儿属实有趣,感觉是 AI 的天然载体,但是一般的板子算力太弱,也只能玩玩。在工程侧,我一直没有找到合适的场景来深入探究人工智能。
人工智能的优势,是在替代人类在某些规律性工作中建立思维方式,以此解决问题。因此,我策划了一个以提升团队效率为目标的AI提效计划,分为三个阶段:请求定位、问题诊断、故障预测。
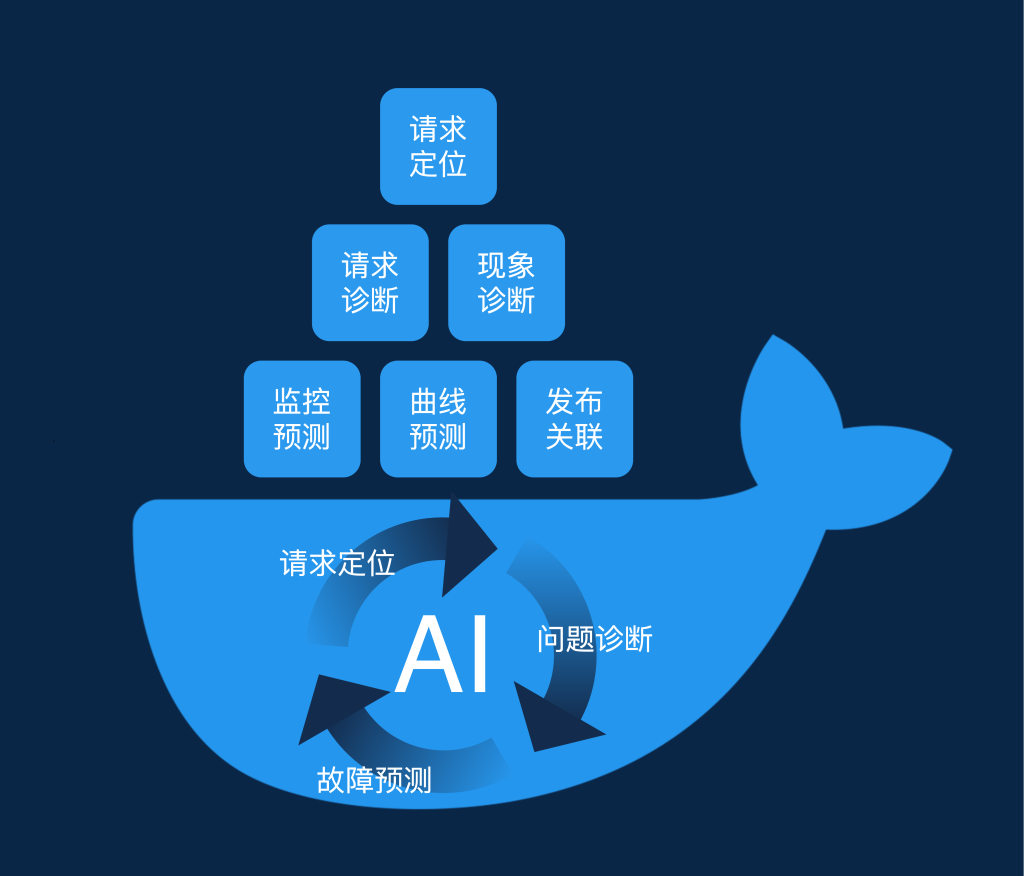
作为工程侧的开发,虽然上手复杂的算法有些困难,但是在一般算法的实际落地和简单优化方面,我还是有很多经验的。第一阶段的请求定位功能是已经实现,本文的后续内容将会对其进行全面的介绍。第二阶段的问题诊断功能分为请求诊断和现象诊断,请求诊断目前已经完成一部分了。我们可以通过全链路日志直接获取整理好的日志中的问题,例如短视频没召回、商品卡主图重复等。现象诊断更为复杂,它需要在巨多的监控和变更中挑出可能导致问题的原因。第三阶段的故障预测目前还在摸索中。
二、技术策略
2.1 数据流程

Source:在DOSA等业务应用中部署信息采集组件,负责数据的上报。
Channel:在倒排索引存储库中为各个业务应用存储相应的数据。
Sink:数据处理后台会从存储库中进行数据召回、混排、解析和阶段。
2.2 技术架构
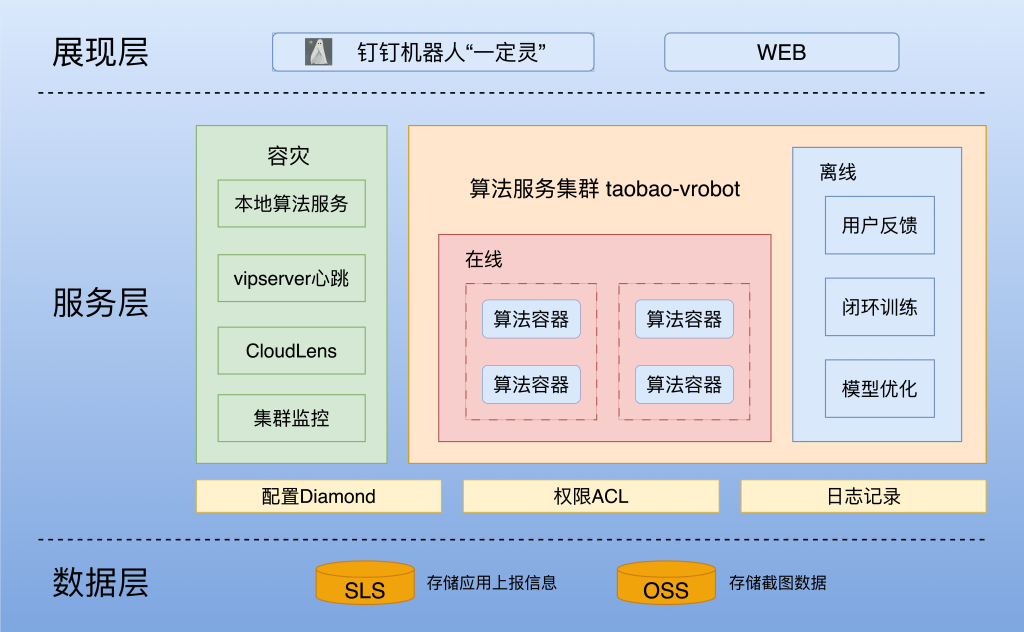
展现层
“请求定位”服务可以通过钉钉机器人“一定灵”直接访问。未来也会开通 Web 渠道,但是集团内的话肯定还是直接与机器人交互更加便捷。
服务层
请求定位服务的配置存储在 Diamond 中,权限系统由ACL负责。同时配有日志系统,用户可向“一定灵”发送指令“log”,机器人就会返回最近一次用户访问功能的日志。
图像识别和分类服务由“一定灵”的算法服务应用 taobao-vrobot 负责,目前可通过 Vipserver 访问。容器目前两两一组,未来流量大的情况下可设置集群计算。同时,“一定灵”会将用户发送的图片上传至OSS,将用户反馈结果上报至 taobao-vrobot,完成闭环训练,不断自优化模型,只需要少许的管理员介入即可。
“一定灵”和 taobao-vrobo t都是 Aone 应用,有集群监控及告警保证。同时在 Aone 本身优秀的负载均衡下,也能保证部分机器故障后,整体服务仍能正常运行。Vipserver 的健康监控保证了 taobao-vrobot 中的图像识别和分类服务接口的正常访问。当“一定灵”无法正常访问 taobao-vrobot,或 taobao-vrobot 返回结果不满足预期时,“一定灵”会使用本地备用的图像识别和定位算法服务。 关于“一定灵”的请求定位服务的本地备用的图像识别和定位算法服务,我之前也写过一篇博客介绍:https://twocups.cn/index.php/2023/08/05/54/
数据层
阿里日志服务SLS负责存储业务数据,对象存储服务OSS负责存储图像数据集及其数据标注信息。用户查询的图片也都会被保存在OSS中,作为下一次迭代训练的正/负反馈数据。
三、方案实现
步骤1:手淘首页的有效信息上报
采集组件vrobot-collection
在DOSA层直接用采集组件对子容器中卡片的有效信息进行采集和上报。
import com.taobao.vrobot.collection.controller.VCClient;
@Autowired
VCClient vrobotCollectionClient;
public void workerFunc() {
...
vrobotCollectionClient.report(info, Project.DOSA);
}其中用到的采集组件是vrobot-collection,是我写的一个简易的信息上报库。vrobot-collection采用的是典型的工厂模式,会在用户进行信息上报之前从工厂中获取相应的上报客户端。如果发现没有注册则会立即进行客户端生成和注册。如果注册失败,那么直接用空客户端占位,防止线上业务高并发下重复注册带来的影响。
存储格式协议
在消息的上报之初就应该考虑消息的存储格式协议了,因为步骤3中是需要基于相同的协议来进行索引的,两者必须保持一致。
SLS在我用过的公司项目中已经是属于好用的那一类了,但是在我们的这个项目中还存在着两个问题:
- SLS的全文索引最多支持前16kb的内容,超过的部分将不会被视作需要建立索引的内容。
- SLS的中文分词逻辑是针对完整词义的。
对于前者,如果我们把DOSA中子容器内容直接上报,那么内容中的有效信息极大概率是不会被建立索引的。对于后者,我们之后是基于截图来获取有效信息的,这意味着我们获取的有效信息往往是残缺的。再加上SLS基于ES的倒排索引机制,让我们很难搜索到相应的内容。(举个简单的例子,在SLS中以“下班”为索引进行搜索有3000条,那么搜索“下班了”可能只有200条,如果不了解倒排索引和分词的话可能觉得这是反直觉的。)
基于此,我自己搞了套简易的数据存储格式协议(被作为工具类写在了vrobot-collection里),主要是为了和后面的查询逻辑对应上。
import com.taobao.vrobot.collection.utils.EncodeUtil;
String encodedReportContent = EncodeUtil.vRobotEncode(reportContent);步骤2:截图中有效信息的定位和分类
钉钉机器人“一定灵”
钉钉机器人“一定灵”是淘宝首页逛信息流团队的稳定性机器人,日常会帮助我们做问题排查,各位可以在钉钉中直接搜到它。对它说“帮助”,它会告诉你它的使用说明。
“一定灵”作为单聊机器人可以接受富文本信息。当用户发送给他图片时,它会将其保存在OSS中,并且将链接发送给后台。后台需要调用图片时,只需要从OSS中下载即可。
图像识别与分类模型与备用算法服务
当“一定灵”接收到用户图片时,会先请求一定灵算法服务应用 taobao-vrobot 中的图像识别与分类服务。正常情况下,该服务会返回图像中识别对象的类型和坐标。若服务超时、空结果、或返回结果不满足预期,则会使用本地备用的图像识别和定位算法服务。你可以通过“一定灵”的“log”指令查看你最近一次的功能调用日志,其中就包括你用的模型名称。本地备用算法服务就不再多说了,上面已经给出了我之前的文章链接,其中的原理、源码和效果都已经描述清楚了。
Yolo模型
一定灵算法服务应用 taobao-vrobot 中的图像识别与分类服务主要是采用 Yolo v8 作为基础模型。我前期通过 LabelImg 对数据集做了数据标注,之后经过 Yolo 多轮训练,也挑选出了最优模型。
以下是模型预测效果图:
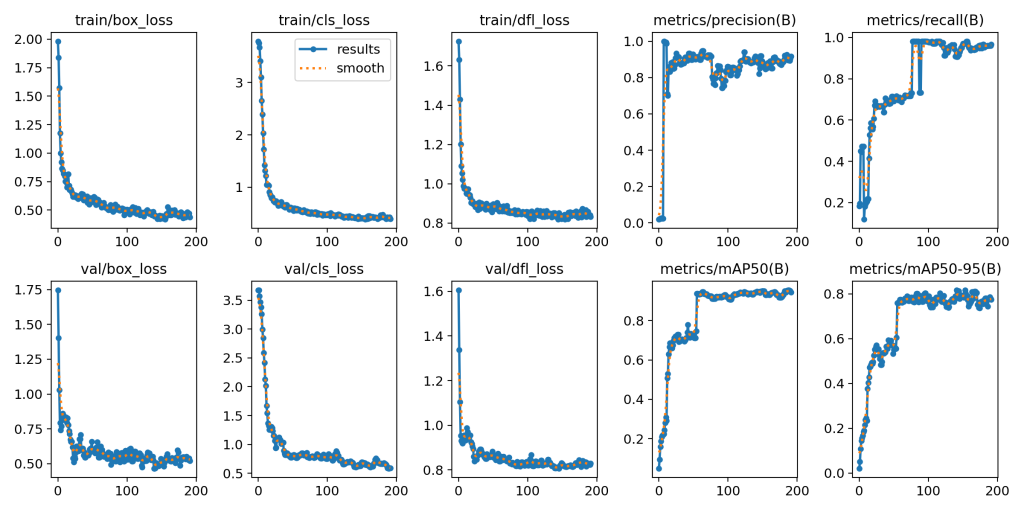
box_loss(边界框损失,越低越好):该损失用于衡量模型预测的边界框与真实边界框之间的差异,这有助于确保模型能够准确地定位对象。
obj_loss(置信度损失,越低越好):该损失用于衡量模型预测的框(即包含对象的矩形)与真实框之间的差异。
cls_loss(分类损失,越低越好):该损失用于判断模型是否能够准确地识别出图像中的对象,并将其分类到正确的类别中。
precision(精确度,越高越好):召回正确的正类和所有正类的比例。
recall(召回率,越高越好):召回正确的正类和召回样本确实是正类的比例。
精确度和召回率是图像识别最经典的两个指标,需要结合着看。举个例子,一个人群中共有5男5女,且识别目标是男性。假设我全部召回,那么精确度是50%,而召回率是100%;假设我召回了1男,那么精确度是100%,而召回率是20%。
之前我还加了 Multi-headed Self-attention(MHSA,多头自注意力机制),但由于手淘首页的场景相对简单,所以原先的模型就已经有很优秀的效果了。MHSA是Transformer及BERT模型中经常用到的一种机制,感兴趣的话可以去搜一下。通俗点来说,一般模型在对当前位置的信息进行编码时,会过度地将注意力集中于自身的位置。多头注意力机制其实就是将一个大的高维单头拆分成了多个多头。一般来说,这个多头的数量越多,模型的表达能力就越强,模型对注意力权重的分配就越合理。

其实 Yolo 的卷积也可以调整,等以后有更复杂的场景再考虑。
“一定灵”与算法服务的通信
“一定灵”后台和 taobao-vrobot 的通信是通过 Vipserver 寻址的。毕竟 taobao-vrobot 只对集团内服务,专门注册一个 DNS 域名用处不大。Vipserver 是集团内的一项很实用的服务,可以将机器分组和 Vipserver 域名继续绑定,后续即时分组内有机器/容器变动,Vipserver 也能正常寻址。同时,Vipserver 提供的健康检查服务很好用,它不但能够检查机器/容器的健康状况,还能定期访问服务接口,检测是否 Active。
图片预处理和OCR
“一定灵”在根据算法返回的图像中对象的分类和坐标信息后,会先做一次图片预处理,生成一张新的图像。该图像除了算法返回的有效对象坐标之外,会将其他所有的色域变白,以此去除多余信息的影响。之后将新图片发送给阿里 OCR 服务,得到图像中有效内容的本文。
闭环训练
图像识别与分类算法服务除了计算当此数据之外,还会将用户请求的图片保存至 OSS,并根据用户反馈将其判定为正向/负向数据。Yolo 模型每周会根据最新的数据集自动重新训练一次,不断优化。
步骤3:基于有效信息的请求定位
“步骤1:手淘首页的有效信息上报”为我们提供了用户请求的数据源,而“步骤2:截图中有效信息的定位和分类”为我们提供了用户查询的目标信息。最后一步就是在数据源中搜索到用户的目标数据。
对于搜索方来说,由于SLS存在中文分词逻辑,所以我们在搜索前需要将搜索数据进行预处理。格式逻辑和步骤1中的数据存储格式协议对的上就行。从SLS得到搜索结果后,我们需要对数据从时间、频次、符合度等方面进行打分和排序,最终得到合适的用户请求排名,并返回给用户。你也可以通过“一定灵”的“log”指令查看这次请求定位服务的日志。如果你得到的用户请求结果非常多,那么有可能是客户端兜底了,或者在手淘预发环境的前几页(预发环境前几页大家的出卡内容都是非常相似的)。
成果
对钉钉机器人“一定灵”发送首页截图,他会把根据截图把相应的用户请求发给你。有时会存在两个请求,是因为首页存在翻页现象,所以两个请求都是正确的。当返回用户请求过多时,说明可能是客户端兜底了,或者预发环境前几页大家的出卡状态是相似的。当然也欢迎反馈各种 Bad Case。
对“一定灵”说“log”,它会把你最后一次请求的功能调用日志打印出来。
写在最后
如果有其他团队也想接入这个服务的话,只需要在业务应用里用vrobot-collection上报数据即可。同时,把训练好的模型提供给我,我来帮你们部署。Yolo模型的话尽量给pt模型,onnx虽然更通用,但需要我再搭一条链路了。当然,这部分的SLS资源和taobao-vrobot中这部分的机器/容器资源也从接入服务的团队资源中提供。
最近我去开了SRE大会,听了若海、裴度等大佬的演讲,发现淘宝虽然是非常典型的业务部门,但是恰恰是为了业务,我们跟需要去关注业务效果之外的事情,例如稳定性、成本、效率,因为它们对业务的效果提升是整体的。同样,AI不是解决所有问题的银弹,但在提效方面的确是一把好手。希望AI能帮助大家从繁杂重复的那部分工作中解放出来,去做一些对团队和业务都更有帮助的事。