
 版权声明:本文为博主原创文章,转载请注明出处:https://twocups.cn/index.php/2021/03/13/32/
版权声明:本文为博主原创文章,转载请注明出处:https://twocups.cn/index.php/2021/03/13/32/
写在前面
今天我们来读一下 Filebeat 的源码。读源码的好处有很多啊,这里就不赘述了。说点实际的,如果想要在现有的软件或系统里做一些深度的定制化,或者在它们的基础上增加、修改、删除一些功能的话,那是必须要去读源码的。其实我挺喜欢读源码的,优秀代码的精彩程度不亚于一部大片,刺激又新奇。可惜我记性不好,和电影一样看完就忘了。不过能大概清楚个架构,也算小有收获了。以后,我读到觉得非常棒的代码都会在 Twocups 里面记录下来,漂亮的代码真是人间惊鸿宴。
读源码的工具有很多啊,我推荐 Understand 和 Source Insight。这两种工具的特点是对于一些不想跳转但又想查看明细的地方,它们可以在软件下方单独开一个小窗口显示,这十分方便(现在 VS Code 也支持这种功能)。还有一个特点是它们的图表十分丰富,例如符号的 butterfly 图、流程图、依赖图、项目的鸟瞰图等,这点上 Understand 做的还要好很多。但是,今天的 Filebeat 的源码我还是用 VS Code 看的,原因是 Understand 和 Source Insight 不支持 Go 语言,而 Filebeat 就是用 Go 写的。虽然 Source Insight 可以装 Go 语言插件,但是这插件几乎没用……
每个人读源码的方式都不同,但都是带着目的去读的,不会有人是按照文件的顺序去读的。读源码不要裸读,读之前先看看有没有文档。把文档看完了,大概知道运行流程或者工作原理了,再带着问题去看源码,事半功倍。而且不要像我之前一样,读完了就没了,最好记点东西下来。以后如果要用到,那可以快速翻看,至少能回忆起大半的内容。
Filebeat 的工作原理
工作原理的官网文档:https://www.elastic.co/guide/en/beats/filebeat/current/how-filebeat-works.html
_filebeat.png)
Filebeat 的架构很庞大,我先大概说一下。Filebeat 会为每一类路径(glob 模式)创建一个 Input(输入)。这个 Input 就相当于 Filebeat 的大主管,它主要管两样东西:Harvester 和 Registry(注册表)。Input 会为每一个文件创建一个 Harvester,并负责它的启动和停止等功能。同时,Input 还会把 Harvester 的相关信息记录到 Registry 中,而 Registry 就是 Harvester 们的注册表。之后,每个 Harvester 对各自的文件读取信息,然后发送到 Spooler 中。等到 Spooler 中的数据累积到一定程度以后,再发送到指定的地方,例如 Elasticsearch、Logstash、Kafka、Redis等。
Filebeat 里面还用到了很多组件并不在 Filebeat 的项目里面,而是在 Beats 项目的 libbeat 库中。这个库非常重要,可以说是所有 Beats 通用功能的底层实现,而 Filebeat 项目只需要实现一些业务逻辑代码,这些在后面梳理 Filebeat 源码的时候全都会说到。
Filebeat 的日志采集流程
我画了一个 Filebeat 的日志采集的流程图,里面描述了 Filebeat 的主要组件采集日志数据的过程。大家可以先看看图,有个大概的印象,我们再详细往下说。
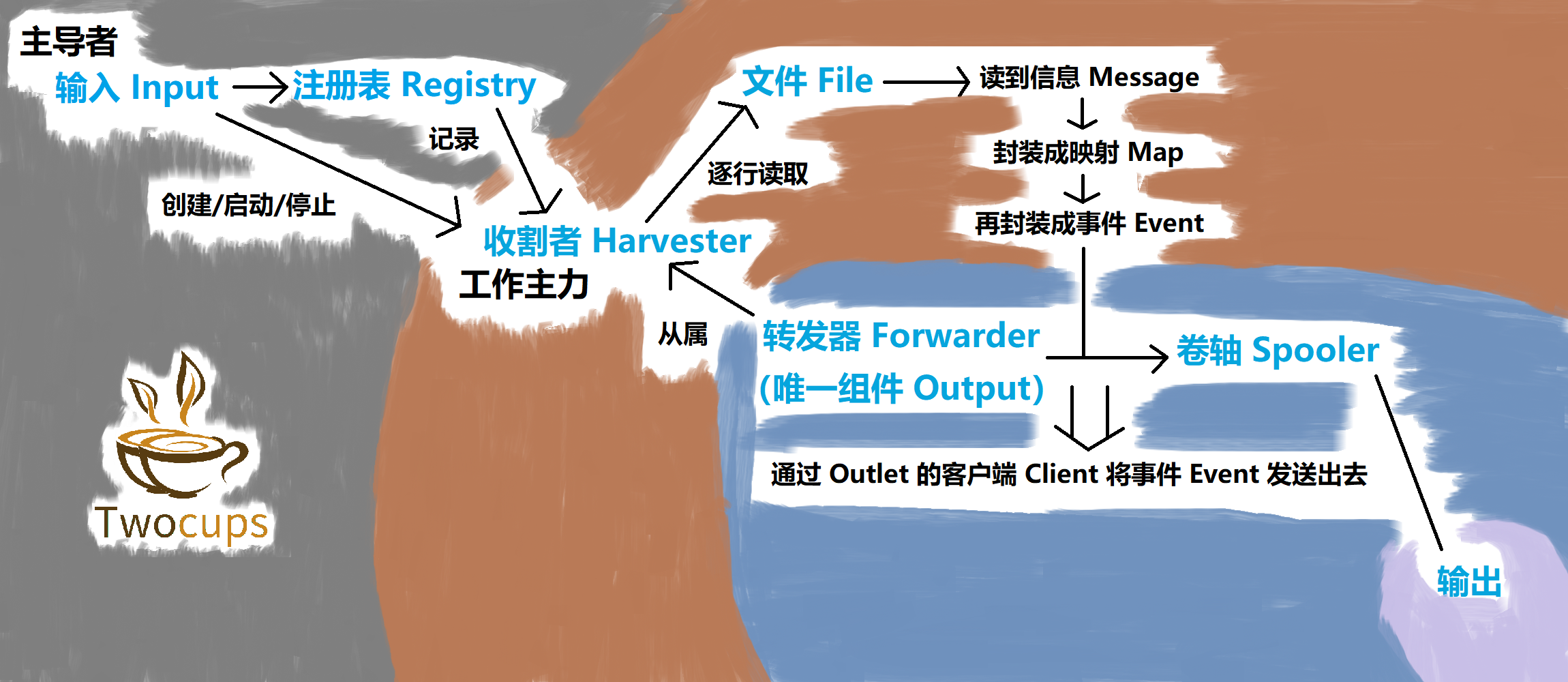
接下来,我们详细看看 Filebeat 的源码中是如何实现日志数据采集的功能的。
首先,当我们从命令行开启 Filebeat 后,Filebeat 会初始化默认的 Inputs,并且执行命令行中我们给出的配置。
// Filebeat主方法
func main() {
if err := cmd.Filebeat(inputs.Init, cmd.FilebeatSettings()).Execute(); err != nil {
os.Exit(1)
}
}
之后更新配置信息,并且运行命令行中的指令。
// beat初始化
func Run(settings Settings, bt beat.Creator) error {
err := setUmaskWithSettings(settings)
if err != nil && err != errNotImplemented {
return errw.Wrap(err, "could not set umask")
}
// 这里的name是beat的名称,即filebeat
name := settings.Name
idxPrefix := settings.IndexPrefix
version := settings.Version
elasticLicensed := settings.ElasticLicensed
return handleError(func() error {
defer func() {
if r := recover(); r != nil {
logp.NewLogger(name).Fatalw("Failed due to panic.",
"panic", r, zap.Stack("stack"))
}
}()
// 根据settings里面得到的beat信息,新建一个beat
b, err := NewBeat(name, idxPrefix, version, elasticLicensed)
if err != nil {
return err
}
// 从Namespace中获得注册表并报告给监视器
// Namespace是一个带锁的注册表结构体,下面给出来了
registry := monitoring.GetNamespace("info").GetRegistry()
monitoring.NewString(registry, "version").Set(b.Info.Version)
monitoring.NewString(registry, "beat").Set(b.Info.Beat)
monitoring.NewString(registry, "name").Set(b.Info.Name)
monitoring.NewString(registry, "hostname").Set(b.Info.Hostname)
// 把状态注册表、服务注册表和beat注册表都报告给监视器
stateRegistry := monitoring.GetNamespace("state").GetRegistry()
serviceRegistry := stateRegistry.NewRegistry("service")
monitoring.NewString(serviceRegistry, "version").Set(b.Info.Version)
monitoring.NewString(serviceRegistry, "name").Set(b.Info.Beat)
beatRegistry := stateRegistry.NewRegistry("beat")
monitoring.NewString(beatRegistry, "name").Set(b.Info.Name)
monitoring.NewFunc(stateRegistry, "host", host.ReportInfo, monitoring.Report)
// 根据设置和beat.Creator启动beat
// beat.Creator是用来创建新beate实例的创建者
return b.launch(settings, bt)
}())
}
// Namespace结构体
type Namespace struct {
sync.Mutex
name string
registry *Registry
}
之后在 Beat 的 launch 方法中,大部分内容都是通过 defer 来在这个 Beat 实例结束后释放资源。之后在 Filebeat 实例的 Run 方法中,Filebeat 中的主要角色们 Register、Publisher、Spooler、Crawler 将被初始化并依次启动。前三个我们都认识,那最后一个启动的 Crawler 是什么呢?crawler 的主要功能是管理所有的 Input。而 Input 里面存有着文件们的状态列表,和文件的 Harvester,并且这些 Harvester 是存在 Registry 里的。
// crawler结构体
type crawler struct {
log *logp.Logger
inputs map[uint64]cfgfile.Runner
inputConfigs []*common.Config
wg sync.WaitGroup
inputsFactory cfgfile.RunnerFactory
modulesFactory cfgfile.RunnerFactory
modulesReloader *cfgfile.Reloader
inputReloader *cfgfile.Reloader
once bool
beatDone chan struct{}
}
// input结构体
type Input struct {
cfg *common.Config
config config
states *file.States
harvesters *harvester.Registry
outlet channel.Outleter
stateOutlet channel.Outleter
done chan struct{}
numHarvesters atomic.Uint32
meta map[string]string
stopOnce sync.Once
fileStateIdentifier file.StateIdentifier
}
// Registry结构体
type Registry struct {
sync.RWMutex
harvesters map[uuid.UUID]Harvester
wg sync.WaitGroup
done chan struct{}
}
这时 Crawler 会开启所有的 Input,并且检查 Module 有没有开启。而 Input 们在被开启后会先初始化,然后通过 Run 方法运行。之后设置 ignore_older 参数,用于过滤不需要采集数据的文件(当然过滤的规则很多,这只是其中之一)。接着 Input 实例执行 scan 方法。
// input实例扫描文件
func (p *Input) scan() {
var sortInfos []FileSortInfo
var files []string
// getFiles方法:返回该input实例下所有必须要收集的文件
// 该方法会展开所有glob,然后过滤目录和排除文件
paths := p.getFiles()
var err error
// 扫描的同时排序文件
if p.config.ScanSort != "" {
sortInfos, err = getSortedFiles(p.config.ScanOrder, p.config.ScanSort, getSortInfos(paths))
if err != nil {
logp.Err("Failed to sort files during scan due to error %s", err)
}
}
if sortInfos == nil {
// 之前得到的paths是map格式的,这里获得键值对中的键,即文件列表
files = getKeys(paths)
}
// 遍历所有需要收集信息的文件
for i := 0; i < len(paths); i++ {
var path string
var info os.FileInfo
if sortInfos == nil {
path = files[i]
info = paths[path]
} else {
path = sortInfos[i].path
info = sortInfos[i].info
}
// 通过共享管道检查input的是否结束
select {
case <-p.done:
logp.Info("Scan aborted because input stopped.")
return
default:
}
// 获取文件的最新读取状态,状态的结构体给在下面了
newState, err := getFileState(path, info, p)
if err != nil {
logp.Err("Skipping file %s due to error %s", path, err)
}
// 判断是否是新增的文件状态
isNewState := p.states.IsNew(newState)
// 忽略所有低于ignore_older配置的文件
if p.isIgnoreOlder(newState) {
err := p.handleIgnoreOlder(isNewState, newState)
if err != nil {
logp.Err("Updating ignore_older state error: %s", err)
}
continue
}
// 如果是新增的文件状态,就为该文件新建一个Harvester
// 如果是已有的文件状态,那就比较新旧文件状态的变换再进行操作
if isNewState {
logp.Debug("input", "Start harvester for new file: %s", newState.Source)
// 为新的文件创建Harvester
err := p.startHarvester(newState, 0)
if err == errHarvesterLimit {
logp.Debug("input", harvesterErrMsg, newState.Source, err)
continue
}
if err != nil {
logp.Err(harvesterErrMsg, newState.Source, err)
}
} else {
lastState := p.states.FindPrevious(newState)
// 将已有文件现在的状态和之前进行对比
p.harvestExistingFile(newState, lastState)
}
}
}
// 文件状态的结构体
type State struct {
Id string `json:"id" struct:"id"`
PrevId string `json:"prev_id" struct:"prev_id"`
Finished bool `json:"-" struct:"-"`
Fileinfo os.FileInfo `json:"-" struct:"-"`
Source string `json:"source" struct:"source"`
Offset int64 `json:"offset" struct:"offset"`
Timestamp time.Time `json:"timestamp" struct:"timestamp"`
TTL time.Duration `json:"ttl" struct:"ttl"`
Type string `json:"type" struct:"type"`
Meta map[string]string `json:"meta" struct:"meta,omitempty"`
FileStateOS file.StateOS `json:"FileStateOS" struct:"FileStateOS"`
IdentifierName string `json:"identifier_name" struct:"identifier_name"`
}
如果 Input 检测到文件状态是新增的,那说明 Input 是第一次遇到这个文件,那么直接为它新建一个 Harvester;如果 Input 检测到这个文件状态是已有的,说明 Input 之前为它启动过 Harvester,那么就需要根据文件是否变动来分情况讨论了。这里文件状态中参与比较的参数有四个:Harvester 的状态是否为已完成、Harvester 所收集的文件的大小、Harvester 读取文件时的偏移量、文件来源(文件名)。
// input实例在文件状态发生变化时的变动
func (p *Input) harvestExistingFile(newState file.State, oldState file.State) {
logp.Debug("input", "Update existing file for harvesting: %s, offset: %v", newState.Source, oldState.Offset)
// 情况1:该文件之前已经停止收集了,但现在文件中有新的内容,所以再对其开启一个Harvester
if oldState.Finished && newState.Fileinfo.Size() > oldState.Offset {
logp.Debug("input", "Resuming harvesting of file: %s, offset: %d, new size: %d", newState.Source, oldState.Offset, newState.Fileinfo.Size())
// 从文件中旧的偏移量处继续收集数据
err := p.startHarvester(newState, oldState.Offset)
if err != nil {
logp.Err("Harvester could not be started on existing file: %s, Err: %s", newState.Source, err)
}
return
}
// 情况2:该文件之前已经停止收集了,并且现在文件被截断了,所以再对其开启一个Harvester
if oldState.Finished && newState.Fileinfo.Size() < oldState.Offset {
logp.Debug("input", "Old file was truncated. Starting from the beginning: %s, offset: %d, new size: %d ", newState.Source, newState.Offset, newState.Fileinfo.Size())
// 既然文件已经被截断了,那么就从文件的开头开始收集数据
err := p.startHarvester(newState, 0)
if err != nil {
logp.Err("Harvester could not be started on truncated file: %s, Err: %s", newState.Source, err)
}
filesTruncated.Add(1)
return
}
// 情况3:文件被重命名,则不需要再开启Harvester
if oldState.Source != "" && oldState.Source != newState.Source {
logp.Debug("input", "File rename was detected: %s -> %s, Current offset: %v", oldState.Source, newState.Source, oldState.Offset)
if oldState.Finished {
// 如果该文件之前已经停止收集了,那么更新文件状态即可
logp.Debug("input", "Updating state for renamed file: %s -> %s, Current offset: %v", oldState.Source, newState.Source, oldState.Offset)
oldState.Source = newState.Source
oldState.TTL = newState.TTL
err := p.updateState(oldState)
if err != nil {
logp.Err("File rotation state update error: %s", err)
}
filesRenamed.Add(1)
} else {
// 如果该文件之前没有被停止收集,那么我们默认旧的Harvester仍在运行,或者不需要新的Harvester
logp.Debug("input", "File rename detected but harvester not finished yet.")
}
}
// 这里不算是新的情况,只是记录Harvester的运行情况
if !oldState.Finished {
logp.Debug("input", "Harvester for file is still running: %s", newState.Source)
} else {
logp.Debug("input", "File didn't change: %s", newState.Source)
}
}
看完上面的代码,很容易有两个疑问。1. 为什么要用文件的大小来判断,用文件的修改时间不行吗?原因是 Windows 的修改时间有可能是不正确的,所以这里只检查文件大小,而不检查文件修改时间。2. 为什么对新增的文件内容和被截断的文件可以分别从旧偏移量和0开始创建 Harvester?因为以上的 Harvester 是仅仅针对日志文件采集的 Harvester,而日志文件不回去修改过去的内容。
上面代码中的 startHarvester 方法将根据文件的 Harvester 的状态和 Harvester 的偏移量创建新的 Harvester。其中会调用 Input 实例中的 Registry 的 Start 方法来启动新的 Harvester。我们之前说过的,Filebeat 中的 Registry 的责任就是记录所有的 Harvester,并且负责启动和停止 Harvester。
// 注册表启动Harvester实例
func (r *Registry) Start(h Harvester) error {
// 此时的Registry是指针指着的地址,所以为了一致性,肯定要先锁上再操作
r.Lock()
defer r.Unlock()
// 确保在Registry调用Stop后没有新的Harvester
if !r.active() {
return errors.New("registry already stopped")
}
// Registry的等待队列新增一员
r.wg.Add(1)
// 把Harvester添加到注册表中
r.harvesters[h.ID()] = h
go func() {
defer func() {
r.remove(h)
r.wg.Done()
}()
// 启动Harvester
err := h.Run()
if err != nil {
logp.Err("Error running input: %v", err)
}
}()
return nil
}
到这里为止,Input 和 Registry 的任务差不多结束了,而下面开始就是 Harvester 开始工作了。首先给出 Harvester 和与之相关的 harvesterProgressMetrics 的结构体。
// Harvester结构体:Harvester本身相关的数据
type Harvester struct {
id uuid.UUID
config config
source harvester.Source
// 停止Harvester时的相关指标,马上就要用到
done chan struct{}
doneWg *sync.WaitGroup
stopOnce sync.Once
stopWg *sync.WaitGroup
stopLock sync.Mutex
// 开启Harvester时的相关指标
state file.State
states *file.States
log *Log
// 读取文件的工具
reader reader.Reader
encodingFactory encoding.EncodingFactory
encoding encoding.Encoding
// 发送信息的工具
outletFactory OutletFactory
publishState func(file.State) bool
// Harvester的工作内容相关的数据,结构体就在下面
metrics *harvesterProgressMetrics
onTerminate func()
}
// harvesterProgressMetrics结构体:Harvester的工作内容相关的数据
type harvesterProgressMetrics struct {
metricsRegistry *monitoring.Registry
filename *monitoring.String
started *monitoring.String
lastPublished *monitoring.Timestamp
lastPublishedEventTimestamp *monitoring.Timestamp
currentSize *monitoring.Int
readOffset *monitoring.Int
}
下面是启动 Harvester 的方法。该方法在启动 Harvester 之前,就已经把停止 Harvester 的相关工作准备好了,之后 Harvester 再逐行读取日志文件中的数据。
// 启动Harvester
func (h *Harvester) Run() error {
// onTerminate 是Harvester实例的一个函数,用于在Harvester结束时执行操作
// 之前Input创建Harvester的时候,将这个函数设为Input实例中存储的Harvester的数量减一
if h.onTerminate != nil {
defer h.onTerminate()
}
// forwarder是outlet的封装,outlet负责发送收集到的日志信息
// outlet和forwarder下面都会给出结构体
outlet := channel.CloseOnSignal(h.outletFactory(), h.done)
forwarder := harvester.NewForwarder(outlet)
// 既然当前Harvester实例启动了,那么就需要使Stop方法的等待队列元素加一
// 这表明了当前Harvester能够停止
// 由于stopWg是共享的,所以需要加锁操作
h.stopLock.Lock()
h.stopWg.Add(1)
h.stopLock.Unlock()
select {
case <-h.done:
h.stopWg.Done()
return nil
default:
}
defer func() {
h.stop()
h.cleanup()
harvesterRunning.Add(-1)
h.stopWg.Done()
}()
harvesterStarted.Add(1)
harvesterRunning.Add(1)
// 单开一个线程:两种情况下停止Harvester
go func(source string) {
closeTimeout := make(<-chan time.Time)
if h.config.CloseTimeout > 0 {
closeTimeout = time.After(h.config.CloseTimeout)
}
select {
// 要么等到超时关闭Harvester
case <-closeTimeout:
logp.Info("Closing harvester because close_timeout was reached: %s", source)
// 要么等到Harvester自己结束
case <-h.done:
}
h.stop()
err := h.reader.Close()
if err != nil {
logp.Err("Failed to stop harvester for file %s: %v", h.state.Source, err)
}
}(h.state.Source)
logp.Info("Harvester started for file: %s", h.state.Source)
h.doneWg.Add(1)
go func() {
h.monitorFileSize()
h.doneWg.Done()
}()
// Harvester开始逐行读取日志文件中的数据
for {
select {
// Harvester完成任务后当前循环结束
case <-h.done:
return nil
default:
}
// Harvester读取日志文件中的一行数据
message, err := h.reader.Next()
// 异常处理
if err != nil {
switch err {
case ErrFileTruncate:
logp.Info("File was truncated. Begin reading file from offset 0: %s", h.state.Source)
h.state.Offset = 0
filesTruncated.Add(1)
case ErrRemoved:
logp.Info("File was removed: %s. Closing because close_removed is enabled.", h.state.Source)
case ErrRenamed:
logp.Info("File was renamed: %s. Closing because close_renamed is enabled.", h.state.Source)
case ErrClosed:
logp.Info("Reader was closed: %s. Closing.", h.state.Source)
case io.EOF:
logp.Info("End of file reached: %s. Closing because close_eof is enabled.", h.state.Source)
case ErrInactive:
logp.Info("File is inactive: %s. Closing because close_inactive of %v reached.", h.state.Source, h.config.CloseInactive)
case reader.ErrLineUnparsable:
logp.Info("Skipping unparsable line in file: %v", h.state.Source)
// 无法解析,直接转到下一行数据
continue
default:
logp.Err("Read line error: %v; File: %v", err, h.state.Source)
}
return nil
}
// 从Harvester实例中拷贝state副本
// 如果不用副本而直接在Harvester实例上操作的话,那么当信息发送失败时,就需要撤销对state的操作了
state := h.getState()
startingOffset := state.Offset
state.Offset += int64(message.Bytes)
// 发送信息
if !h.onMessage(forwarder, state, message, startingOffset) {
return nil
}
// 信息发送成功了,就可以根据副本更新Harvester实例的state了
h.state = state
// 更新harvesterProgressMetrics的相关数据,它的结构体之前给出来了
h.metrics.readOffset.Set(state.Offset)
h.metrics.lastPublished.Set(time.Now())
h.metrics.lastPublishedEventTimestamp.Set(message.Ts)
}
}
// outlet结构体
type outlet struct {
client beat.Client
isOpen atomic.Bool
done chan struct{}
}
// forwarder结构体
type Forwarder struct {
Outlet Outlet
}
以上代码中,Harvester 的 onMessage 方法会更新 Harvester 的状态,并且将 Harvester 的阅读器 reader 读到的一行日志数据发送出去。那么这行日志数据会发送到哪里呢?我们下一篇再说。
Filebeat 的数据发送流程
我又画了一个 Filebeat 的数据发送的流程图,里面描述了 Filebeat 和 libbeat 库中的主要组件发送日志数据的过程。

接下来,我们详细看看 Filebeat 和 libbeat 库的源码中是如何实现日志数据发送的功能的。
上一篇说到 Harvester 会将 reader 读到的日志数据发送出去,那么是发送到哪里呢?在此之前,我们先看两种数据结构:BufferingEventLoop 和 DirectEventLoop。它们俩会根据情况在 libbeat 库中 broker 包被导入的时候进行初始化。
// 缓冲队列bufferingEventLoop结构体
type bufferingEventLoop struct {
broker *broker
buf *batchBuffer
flushList flushList
eventCount int
minEvents int
maxEvents int
flushTimeout time.Duration
// broker接口管道
events chan pushRequest
get chan getRequest
pubCancel chan producerCancelRequest
// 处理应答信号
acks chan int
schedACKS chan chanList
pendingACKs chanList
ackSeq uint
// 缓冲区刷新计时器状态
timer *time.Timer
idleC <-chan time.Time
}
// 直接传递队列directEventLoop结构体
type directEventLoop struct {
broker *broker
buf ringBuffer
// broker接口管道
events chan pushRequest
get chan getRequest
pubCancel chan producerCancelRequest
// 处理应答信号
acks chan int
schedACKS chan chanList
pendingACKs chanList
ackSeq uint
}
DirectEventLoop 结构相对更简单,直入直出,接收到数据就发送出去。而 BufferingEventLoop 会在 broker 接口管道接收到数据时,先将数据放入缓存区。等到缓存区满了之后,会触发 handleConsumer 方法,一次性把数据全部发送出去。
// 缓冲队列bufferingEventLoop运行流程
func (l *bufferingEventLoop) run() {
var (
broker = l.broker
)
for {
select {
case <-broker.done:
return
// 如果缓冲队列接收到了新的event,那就将其插入队列,并检查队列是否已满
case req := <-l.events:
l.handleInsert(&req)
// 如果缓冲队列接收到了移除event的型号,那就移除相依的event
case req := <-l.pubCancel:
l.handleCancel(&req)
// 如果缓冲队列接收到了consumer发送来的请求下一批数据的信号,那就把数据发送过去
case req := <-l.get: // consumer asking for next batch
l.handleConsumer(&req)
case l.schedACKS <- l.pendingACKs:
l.schedACKS = nil
l.pendingACKs = chanList{}
case count := <-l.acks:
l.handleACK(count)
case <-l.idleC:
l.idleC = nil
l.timer.Stop()
if l.buf.length() > 0 {
l.flushBuffer()
}
}
}
}
BufferingEventLoop 这种数据结构将中转的特性发挥的淋漓尽致。它在 broker 包被导入时就已经初始化,之后一边等待 Filebeat 给它发送数据,一遍等待 Consumer 问它要数据。这也就是 Spooler 的底层原理。
之前我们已经说了 Filebeat 是如何给它发送数据的,那 Consumer 是如何问它要数据的呢?Consumer 的 loop 方法能够从缓冲队列的 Broker 中获取日志数据,之后再发送到 outputGroup 的管道 workQueue 中。
// Consumer的loop方法中获取日志数据并且发送出去的循环
func (c *eventConsumer) loop(consumer queue.Consumer) {
log := c.logger
log.Debug("start pipeline event consumer")
var (
out workQueue
batch Batch
paused = true
)
handleSignal := func(sig consumerSignal) error {
switch sig.tag {
case sigStop:
return errStopped
case sigConsumerCheck:
case sigConsumerUpdateOutput:
c.out = sig.out
case sigConsumerUpdateInput:
consumer = sig.consumer
}
paused = c.paused()
if c.out != nil && batch != nil {
out = c.out.workQueue
} else {
out = nil
}
return nil
}
for {
if !paused && c.out != nil && consumer != nil && batch == nil {
// out是outputGroup的管道workQueue
out = c.out.workQueue
// 向Broker发送日志数据的请求,然后等待回复
queueBatch, err := consumer.Get(c.out.batchSize)
if err != nil {
out = nil
consumer = nil
continue
}
if queueBatch != nil {
batch = newBatch(c.ctx, queueBatch, c.out.timeToLive)
}
paused = c.paused()
if paused || batch == nil {
out = nil
}
}
select {
case sig := <-c.sig:
if err := handleSignal(sig); err != nil {
return
}
continue
default:
}
select {
case sig := <-c.sig:
if err := handleSignal(sig); err != nil {
return
}
// 将刚才从Broker那里请求来的数据,发送到outputGroup的管道workQueue
case out <- batch:
batch = nil
if paused {
out = nil
}
}
}
}
// outputGroup结构体
type outputGroup struct {
workQueue workQueue
outputs []outputWorker
batchSize int
timeToLive int
}
// 管道workQueue
type workQueue chan publisher.Batch
随后,outputGroup 的管道 workQueue 中的日志数据又被发送到 clientWorker 中的 worker 中的管道 workQueue 里面。clientWorker 在接收到日志数据后,再用相对应的 Client 的 Publish 方法把日志数据发送出去。
// clientWorker接受并且发送日志数据
func (w *clientWorker) run() {
for {
select {
// 要么worker被关闭
case <-w.done:
return
// 要么从worker中的管道workQueue里面接收到了日志数据
case batch := <-w.qu:
if batch == nil {
continue
}
w.observer.outBatchSend(len(batch.Events()))
// 将接收到的日志数据用相对应的client的Publish方法发送出去
if err := w.client.Publish(context.TODO(), batch); err != nil {
return
}
}
}
}
// clientWorker结构体
type clientWorker struct {
worker
client outputs.Client
}
// worker结构体
type worker struct {
id uint
observer outputObserver
qu workQueue
done chan struct{}
}
// 管道workQueue
type workQueue chan publisher.Batch
Client 有很多种,libbeat 库中包含了 Elasticsearch、logstash、kafka 等的 Client,并且它们的 Publish 方法也有所不同。如果说我们想将 Filebeat 发送到我们自定义的后端,那么就要编写我们自己的 Client,并实现其中的方法。
// Client接口
type Client interface {
Close() error
Publish(context.Context, publisher.Batch) error
String() string
}
写在最后
以上的源码分析只是 Filebeat 采集日志数据并发送到后端的流程,其实还有很多地方没有说清楚,比如 Filebeat 运行时用到了 libbeat 库中的许多包,这些包早在一开始就初始化并发挥了很重要的作用。例如实现 Spooler 的 BufferingEventLoop,它是直接保存在内存中的队列,其实还有保存在硬盘中的队列,也发挥了重要的作用。Filebeat 能够运行,不光是靠一两条主线就能完成了,而是靠着许许多多收发数据的组件合作进行数据传递。又比如说 Elasticsearch、logstash、kafka 等的 Client 及其 Publish 方法也没有详细说,如果能把这些弄懂的话,是可以控制 Filebeat 将采集到的数据发送到我们自己定制的后端。
除了定制后端,Filebeat 能延伸的地方还有很多。例如不使用 Logstash,而是在 Filebeat 传递数据的某个过程中定制一个模块,去专门对数据进行我们想要的过滤或处理,这部分属于自制 Processor 插件。又例如我们在分布式环境下,可以让 Filebeat 去配合 k8s 做容器集群的日志采集。再例如,我们完全可以从 Filebeat 的源码层面对其进行效率优化,比如将 Client 的 Publish 操作并行化从而提升 Filebeat 传输数据的效率。再进一步,我们甚至可以做 Filebeat 的自研,即专属 Filebeat。不过这些也先不着急,我们日后再说。
下篇继续
【Elastic Stack系列】第四章:源码分析(二) Metricbeat篇